
この記事は約 13 分で読めます。
- 名寄せとは
- 名寄せが必要とされる理由
- 入力ミスや表記ゆれによる情報の重複防止
- システム統合時のデータ整備の必要性
- 情報更新の漏れを防ぐため
- 名寄せの手法とアルゴリズム
- ルールベース型名寄せ
- AI・機械学習を活用した名寄せ
- 類似度マッチングによる照合
- 名寄せを実施すべき企業の特徴とは
- 古いデータと最新情報が混在している企業
- 複数チャネルで販売や接点を持っている企業
- 企業統合やシステム移行を予定している企業
- SFA・CRM・MAなどのツールを活用している企業
- 名寄せを活用したリードデータ整理の手順
- 1.対象データの調査・選別
- 2.データの抽出と整形
- 3.データクレンジングの実施
- 4.データのマッチングと統合
- 名寄せを通じたリード活用と商談機会の最大化
- 営業・マーケティング部門での活用メリット
- SFA・MAとの連携による商談創出
- 名寄せがもたらす組織全体の業務効率化
- 名寄せを実施する前に注意すべきこと
- 1.プライバシーと情報漏えいリスクへの配慮
- 2.名寄せルールとツールの仕様を事前に明確化する
- 3.データクレンジングの質を高める
- 4.名寄せが不要な環境を整備する意識も重要
- 名寄せツールの比較ポイント
- 1.マッチング精度と処理方式
- 2.参照可能な外部データの質と量
- 3.名寄せ後の活用設計まで想定できるか
- 4.自社の課題に合った機能構成か
- 5.運用サポートと導入後の安心感
- おすすめ名寄せツール4選
- Sales Marker
- Sansan Data Hub
- Excel
- uSonar
- 本記事のまとめ
営業リストに同じ企業が重複して登録されていたり、過去の接点が記録されていなかったりするデータの乱れは、営業やマーケティングの成果を大きく左右します。
名寄せは、分散・重複した顧客情報を正確に統合し、データを使える状態に整えるための手法です。近年では、ただの情報整理にとどまらず、商談タイミングの最適化やリード精度の向上にも活用されています。
本記事では、名寄せの基本的な意味から、具体的な手法・ツールの選び方、そして営業成果につなげるための活用法まで、わかりやすく解説していきます。
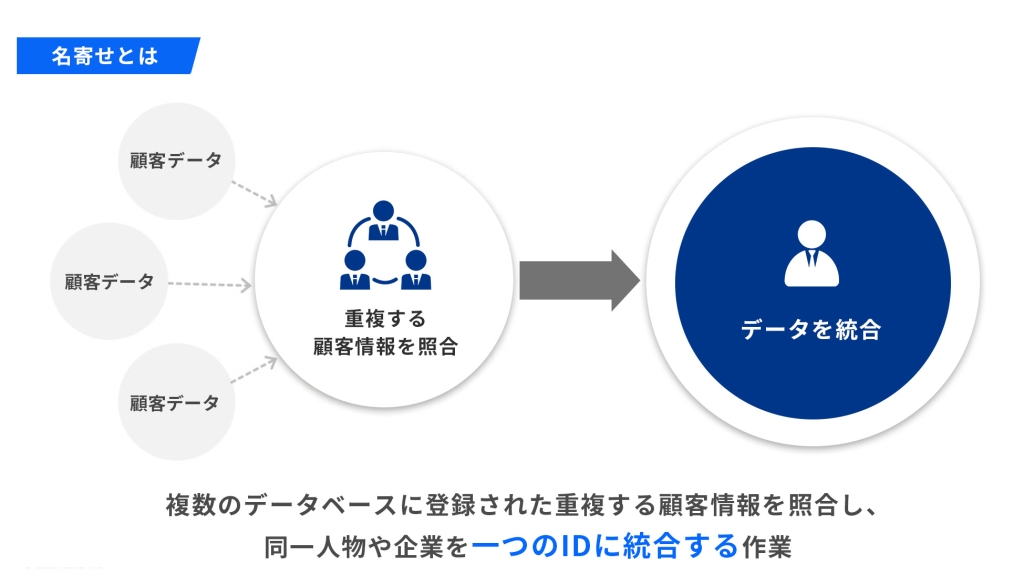
名寄せとは
名寄せとは、複数のデータベースに登録された重複する顧客情報を照合し、同一人物や企業を一つのIDに統合する作業を指します。
氏名や住所、生年月日、電話番号、メールアドレスなどの情報をもとに一致を確認し、同一と判断できる場合にデータをまとめます。
この作業により、情報の重複や誤登録を防ぎ、業務効率や正確な分析につなげることが可能となります。
名寄せが必要とされる理由
名寄せは、情報の重複や不整合を解消し、正確な顧客管理を実現するために欠かせません。
ここでは、名寄せが求められる代表的な理由を見ていきます。

入力ミスや表記ゆれによる情報の重複防止
データ入力時の表記ゆれや人為的なミスは、同一人物が別人として登録される原因となります。「株式会社」と「(株)」、tなど、表記の違いが誤認識につながります。
こうしたミスを防ぐには、名寄せによる統合に加えて、入力ルールの明確化と従業員の教育が重要です。
システム統合時のデータ整備の必要性
システム移行や合併の際、異なる形式のデータが統一されず、重複登録が発生するケースがあります。「ABC株式会社」と「エービーシー株式会社」など、表記差による誤登録は名寄せで統一が必要です。
マッピングルールを事前に定義し、データクレンジングを行うことで、正確な統合作業が可能になります。
情報更新の漏れを防ぐため
住所や連絡先などの変更が全システムに反映されず、古い情報が残る場合もあります。例えば、営業部門のみが最新住所を登録しており、他部門は旧住所のままという状況です。
名寄せにより情報の一元化を図れば、部門間で正しい顧客情報を共有でき、対応ミスを防げます。
名寄せの手法とアルゴリズム
名寄せには、データの性質や目的に応じた複数の手法が存在します。ここでは実務でよく使われる3つの代表的なアプローチについて紹介します。
ルールベース型名寄せ
ルールベース型は、「全角と半角を統一する」「空白・記号を除去する」など、事前に定義したルールに基づいて、機械的にデータを照合・統合する手法です。
導入しやすく、ルールの透明性と制御性が高いため、管理・再現性に優れています。一方で、複雑な表記ゆれや例外パターンには弱く、柔軟な対応には限界があります。
名寄せ対象が限定的で、データ構造が比較的シンプルな場合に適している手法と言えるでしょう。CDPやCRM内の一部フィールド統合などに向いていますが、運用にはルール設計力が求められます。
AI・機械学習を活用した名寄せ
AI・機械学習型は、大量の名寄せ事例を学習データとし、「どのような類似パターンが同一人物か」をアルゴリズムに習得させる方式です。
経験則に基づく判断を自動化できるため、表記揺れや誤入力を含んだ複雑なデータでも、高い精度で名寄せが可能です。未定義のパターンにも対応できる点が大きな強みです。
ただし、精度は学習データに依存し、誤判定のリスクもゼロではありません。また、ブラックボックス化しやすく、結果の説明性や運用の属人化にも注意が必要です。データ量が多く変動も大きい企業や、複数部門・サービス横断の統合に適した手法と言えるでしょう。
類似度マッチングによる照合
類似度マッチングは、文字列や数値の一致率を数値化して、一定以上のスコアを持つものを「同一」とみなすアルゴリズムを使った名寄せ手法です。
Jaccard係数や編集距離(レーベンシュタイン距離)などが代表的なスコア算出法で、「ヨシダ」と「吉田」や「エービーシー」と「ABC株式会社」などにも対応可能です。
閾値の設定次第で厳密にも緩やかにも調整できるため、幅広いシーンで使えますが、判定結果にグレーゾーンが生まれやすく、誤マッチや漏れの検証が必要です。他手法と併用することでバランスよく運用できるため、特にハイブリッド運用に向いています。
名寄せを実施すべき企業の特徴とは
名寄せはすべての企業に必要な作業ではありませんが、特定の条件を満たす企業にとっては必須の施策となります。ここでは、名寄せの導入を積極的に検討すべき企業の共通点について紹介します。
古いデータと最新情報が混在している企業
長年蓄積された顧客情報の中には、住所変更や退職などで既に無効となった情報も多く含まれます。こうした情報を放置しておくと、誤送信や対応ミスの原因になりかねません。
名寄せと同時に定期的なデータ更新を実施することで、顧客情報の鮮度と正確性を保ち、質の高い営業・マーケ活動につなげられます。
複数チャネルで販売や接点を持っている企業
実店舗・ECサイト・電話受注・アプリなど、複数の接点を持つ企業では、チャネルごとにバラバラの顧客IDや購買履歴が生成されてしまうことがあります。
名寄せを通じて各チャネルの情報を横断的に統合すれば、顧客ごとの購買傾向や行動履歴を包括的に捉えることが可能になります。
企業統合やシステム移行を予定している企業
M&Aや再編、システムのリプレースなどが発生するタイミングでは、異なる構造のデータを統合する必要があり、表記のズレや重複が問題化しがちです。
このような局面では、名寄せを事前に行うことでデータのクレンジングが進み、統合後もスムーズに業務を引き継げる状態を整えることができることでしょう。
SFA・CRM・MAなどのツールを活用している企業
営業支援やマーケティングの自動化ツールを導入している企業では、各ツール間で顧客データを正確に連携させる必要があります。
名寄せによりデータの粒度や構造を統一すれば、ツールの機能を最大限に活かせます。施策の精度が上がり、顧客ごとの最適なアプローチやナーチャリングも可能となります。
名寄せを活用したリードデータ整理の手順
ここでは、名寄せを実施する際に押さえるべき4つの基本手順について、具体例を交えながらわかりやすく解説していきます。
1.対象データの調査・選別
まず最初に行うべきは、名寄せ対象となるデータの構造や記載状況を確認する作業です。氏名・住所・電話番号など、照合に使う項目がどのように登録されているかを把握します。
この段階で、どのデータを統合し、どれを除外するかといった方針も定めておくと、後の工程がスムーズに進み、誤った統合を避けることができます。
2.データの抽出と整形
次に、名寄せに必要な情報をデータベースから抽出し、比較可能な状態に整える工程です。このとき、データ項目の名称や形式の違いに注意が必要です。
たとえば「住所」と一口に言っても、「郵便番号+都道府県+市区町村」といった構造の違いがある場合もあります。抽出と同時に整形(標準化)を行うことで、後のマッチング精度が大きく向上します。
3.データクレンジングの実施
抽出したデータは、そのままでは照合精度が低いため、整備・修正を行うクレンジングが必要です。特に日本語特有の表記ゆれや、誤入力の修正は名寄せにおいて重要なポイントとなります。
たとえば、「株式会社ABC」と「(株)エービーシー」や、「3-1-14」と「3丁目1番14号」など、形式は違っても同一の意味を持つ表記を、共通ルールで統一する必要があります。この工程を丁寧に行うことで、名寄せ全体の精度が格段に高まります。
4.データのマッチングと統合
クレンジングが完了したら、いよいよ照合・統合のフェーズに入ります。ここでは、氏名や住所、電話番号などの属性情報をもとに、同一人物・企業を特定していきます。
完全一致だけでなく、あらかじめ定めた「類似度」や「ルール」に基づいて判断することで、表記の違いにも柔軟に対応し、正確な名寄せを実現できます。同一と判断されたデータには一意のIDを付与し、今後の重複や更新漏れを防ぐことを忘れずに行いましょう。
名寄せを通じたリード活用と商談機会の最大化
名寄せによってデータが整理されると、顧客理解の精度が向上し、営業・マーケ・カスタマー対応の各部門での活用価値が一気に広がります。
ここでは、名寄せが実際の業務や商談創出にどう貢献するのか、具体的なメリットを通して解説していきます。
営業・マーケティング部門での活用メリット
名寄せによって顧客データが正確かつ一元的に管理されると、営業やマーケティングにおける情報の重複や誤認識がなくなり、アプローチの精度が大きく向上します。
具体例として、過去に別々のIDで管理されていた同一顧客の履歴が統合されることで、購買傾向や検討期間、過去対応の履歴をもとにした適切な提案が実現できるケースなどが該当します。
SFA・MAとの連携による商談創出
名寄せによって整理された顧客情報をSFAやMAと連携することで、リード育成や案件化までの流れが自動化・可視化され、マーケと営業の分断も解消されていきます。
たとえば、展示会で名刺交換した顧客と、過去に資料請求をしていた顧客が同一人物だった場合、名寄せがなければ別扱いになりますが、統合されていれば最適なタイミングでアプローチできます。

名寄せがもたらす組織全体の業務効率化
情報の更新漏れや部署ごとの重複対応といった非効率は、名寄せによって大幅に削減できます。全社員が最新の顧客情報にアクセスできる状態は、営業活動の精度とスピードを支えます。
また、CRMや社内DBのクレンジングにかかる工数も削減され、レポート精度も高まります。これにより、現場はより本質的な活動に集中でき、組織全体の生産性向上にも直結することでしょう。
名寄せを実施する前に注意すべきこと
名寄せは、顧客情報を統合し、営業やマーケティングの精度を高める重要な施策です。しかし、正確に機能させるためには、実施前にいくつか注意すべき点があります。
ここでは、トラブルを未然に防ぎ、名寄せの効果を最大化するための4つの注意ポイントを紹介します。
1.プライバシーと情報漏えいリスクへの配慮
名寄せでは氏名・住所・連絡先などの個人情報を扱うため、誤った統合によるトラブルに注意が必要です。とくに同姓同名の人物を同一と誤認した場合、無関係の相手にメールや資料を送ってしまうリスクがあります。
こうした誤送信は、個人情報漏えいとして社会的信用の損失につながるおそれがあります。最終的なマッチング結果に対しては必ず確認工程を設け、データ管理体制も強化しておくべきです。
2.名寄せルールとツールの仕様を事前に明確化する
ルールベース型やAI型など、名寄せ手法には複数の選択肢がありますが、どのような条件で「同一」と判定するかの基準は、必ず事前に設計しておく必要があります。
また、名寄せツールを活用する場合は、そのツールが自社の要件に合っているかの確認も不必要です。大量データ処理に強いか、他システムと連携できるかなど、製品ごとの特徴を比較して選びましょう。
3.データクレンジングの質を高める
名寄せの精度を左右するのが、事前の「データクレンジング」です。表記ゆれや誤字・脱字が残ったままでは、正確な照合ができず、統合の精度が大きく低下します。
「㈱」と「株式会社」や、「3丁目1−14」と「3-1-14」など、表記ルールを定めて統一しましょう。そのためには社内で表記基準をマニュアル化し、監査やダブルチェック体制も整えておくことが有効です。
4.名寄せが不要な環境を整備する意識も重要
名寄せ作業は、元をたどれば「データの重複や分断」が原因です。つまり、将来的には名寄せの必要がない状態を目指すべきとも言えます。
たとえば、顧客IDの導入や入力時の重複チェックの自動化、システム間のAPI連携など、データが初めから整った状態で蓄積される仕組みを構築することが理想です。
名寄せツールの比較ポイント
名寄せツールは種類が多く、目的や業務環境に応じて選び方も変わります。ここでは、自社に最適な名寄せツールを選ぶために確認すべき5つの比較ポイントを紹介します。
1.マッチング精度と処理方式
名寄せの土台となるのは「どこまで同一とみなすか」の判断ロジックです。完全一致だけでなく、略称・記号違い・表記ゆれなどに対応できるかを確認しましょう。
また、曖昧なデータに対して自動・手動の判定を切り替えられるような運用の柔軟性も重要です。誤統合を防ぎながら、作業負担を最小限に抑える工夫ができるツールかを見極めてください。
2.参照可能な外部データの質と量
照合処理の精度は、利用する外部データの信頼性に大きく左右されます。法人名辞書や住所辞書、電話番号マスタなど、照合精度を支える基盤データが充実しているかをチェックしましょう。
さらに、企業属性情報や法人番号などを自動付与できる機能があれば、営業データの拡張やCRMの質的向上にもつなげられます。
3.名寄せ後の活用設計まで想定できるか
名寄せは目的ではなく手段です。重要なのは、整備したデータをどう業務に生かすかです。SFA・CRM・マーケツールなどとの接続性や、データ分析への応用範囲も含めて考えましょう。
たとえば、名寄せで整理した顧客情報にスコアや属性を付けられる仕組みがあれば、ターゲティングやアプローチの精度が格段に上がることでしょう。
4.自社の課題に合った機能構成か
「機能が多い=良いツール」ではありません。自社の課題に対して最短距離で効果を出せるかが大切です。大量データ処理・リアルタイム照合・小規模データの手動名寄せなど、目的によって求められる条件は異なります。
営業支援を重視する企業であれば、MAやABMツールとの連携性を。顧客管理の一元化を重視する企業であれば、データ整備力やID管理の仕組みを優先しましょう。
5.運用サポートと導入後の安心感
名寄せはデータ基盤に直結する作業のため、正しく運用できる環境整備も必要です。ツールの習熟支援・運用設計の相談・問い合わせ対応のスピードなど、ベンダーの体制にも注目しましょう。
特に、初期設計を誤ると誤統合や統合漏れのリスクが高まるため、専門家の支援を受けられるプランがあるかも選定基準のひとつです。
おすすめ名寄せツール4選
最後におすすめの名寄せツールを4つ紹介します。
Sales Marker

Sales Markerは、法人番号や企業名をキーにリード情報を整備する名寄せ機能を持ち、企業属性の自動付与や表記ゆれの統合を通じて、営業リストの質を高められます。
一般的な名寄せツールとの違いは、「インテントデータ」を活用している点にあります。企業の購買意欲や検索動向をもとに、最適な営業タイミングまで把握できます。
単にデータを統合するだけでなく、リアルタイムで関心を示す企業の動向を可視化し、タイミングを逃さず提案できる仕組みは、BtoB営業の成果に直結します。
リード情報を整えるだけでなく、動かすまで視野に入れたい企業にとって、Sales Markerは極めて実践的なデータ起点の営業支援サービスといえるでしょう。

Sansan Data Hub

Sansan Data Hubは、Sansanが提供する法人向けのデータ統合ツールです。名刺情報を基点に、CRMやSFA、MAなどの各種システムと自動連携が可能です。
顧客データの統合や企業コードの付与、属性情報の付加などに対応し、社内に点在する情報を整備することで、営業やマーケ施策の土台を構築できます。
また、拡張ドライバを活用すればETLやDWH、BIツールとの接続もスムーズに。蓄積された顧客データを、他部門でも横断的に活用できるようになります。
費用は要問い合わせとなっており、初期費用や運用支援費、月額ライセンス費用が発生する設計です。導入時の支援体制も提供されています。
名刺管理とデータ統合を組み合わせたい企業にとって、Sansanユーザーとの親和性が非常に高い名寄せツールといえるでしょう。
Excel

Excelやアドイン、外部ツールを組み合わせれば、表記ゆれや重複の解消にも活用できます。軽微な名寄せ作業であれば、身近なツールでの対応も十分に可能です。
ただし、Excelは手入力作業が多く、数式の誤削除やセル位置のズレといったリスクがつきものです。複数人で管理する場合、誤操作によってデータの信頼性が損なわれる可能性があります。
uSonar
uSonarは、日本最大級の法人データベース「LBC」を基盤とした顧客統合システムです。SFAやMA、CRMと連携し、自動で名寄せやデータ更新を行うことが可能です。
古い企業データを最新情報へ自動で照合・置換できるほか、移転や倒産情報の精査にも対応しているのが特徴です。分散している社内データも統合し、見込み度の高い企業抽出にも活用されています。
名寄せに加え、営業戦略の基盤となる企業情報の強化を目指す企業にとって、uSonarは拡張性ともに高い選択肢といえるでしょう。
本記事のまとめ
名寄せは、企業に蓄積された重複・誤記・表記ゆれのあるデータを整理し、顧客情報の正確性を高めることで、営業・マーケ施策の精度を大きく向上させます。
データ統合にとどまらず、インテントデータや企業属性を掛け合わせることで、最適なタイミングでの提案や、スコアリングによる見込み客の抽出にもつながります。
Excelやスプレッドシートでも一定の対応は可能ですが、管理の属人化や精度の限界もあります。高度な名寄せを行い、業務に活かすには、ツールの導入と運用設計が必要となることでしょう。
名寄せは情報整理の手段ではなく、成果を生む基盤であるという視点で、自社のデータ環境と照らし合わせながら、導入と活用を検討していきましょう。


